Maximizing ROI By Reducing Cost of Downstream Observability Platforms With BindPlane OP

When engaging with potential customers, we are often asked, “How can we reduce spend on our observability platform like Splunk or Data Dog and simultaneously justify the cost of BindPlane OP?”
Let’s dive in and see how the powerful capabilities of BindPlane OP can reduce your total ingest, and get a positive ROI on your BindPlane OP investment.
How Do We Define ROI?
Downstream observability platforms can be very expensive. Often, huge sums of raw log data are ingested into tools like Splunk and then indexed & analyzed later on. While it would seem like having all that data at your fingertips is great, we’ve found that there is a lot of noise and erroneous information ingested into these platforms. The important and useful data that organizations depend on is often a fraction of what is ingested in total. BindPlane OP can maximize your Return on Investment by reducing, parsing, and filtering this raw data upstream, before making its way to your favorite flavor of observability platform.
What ROI Factors Do We Consider?
- Analyze overall spend of your observability platform. This includes:
- Licensing costs
- Ingestion volume
- Infrastructure costs
- Projected growth of data volume Year-over-Year
- Contractual obligations + vendor lock-in
Tactics We Use to Reduce Observability Costs
- Filtering signal from noise
- Dropping data you don’t need
- Routing to low-cost storage
- Converting Logs to Metrics
- Removing Duplicate logs
- Saving costs with aggregator nodes
Let’s look at how we implement each of these tactics in BindPlane OP.
Filtering
Using a processor, you can reduce the amount of trivial logs by filtering out logs you don’t care about. Let’s say you don’t care about any logs that have a severity below ERROR. You can add a new “Severity Filter” processor to your pipeline and set the severity to ERROR. It will automatically filter out all lower severity types.
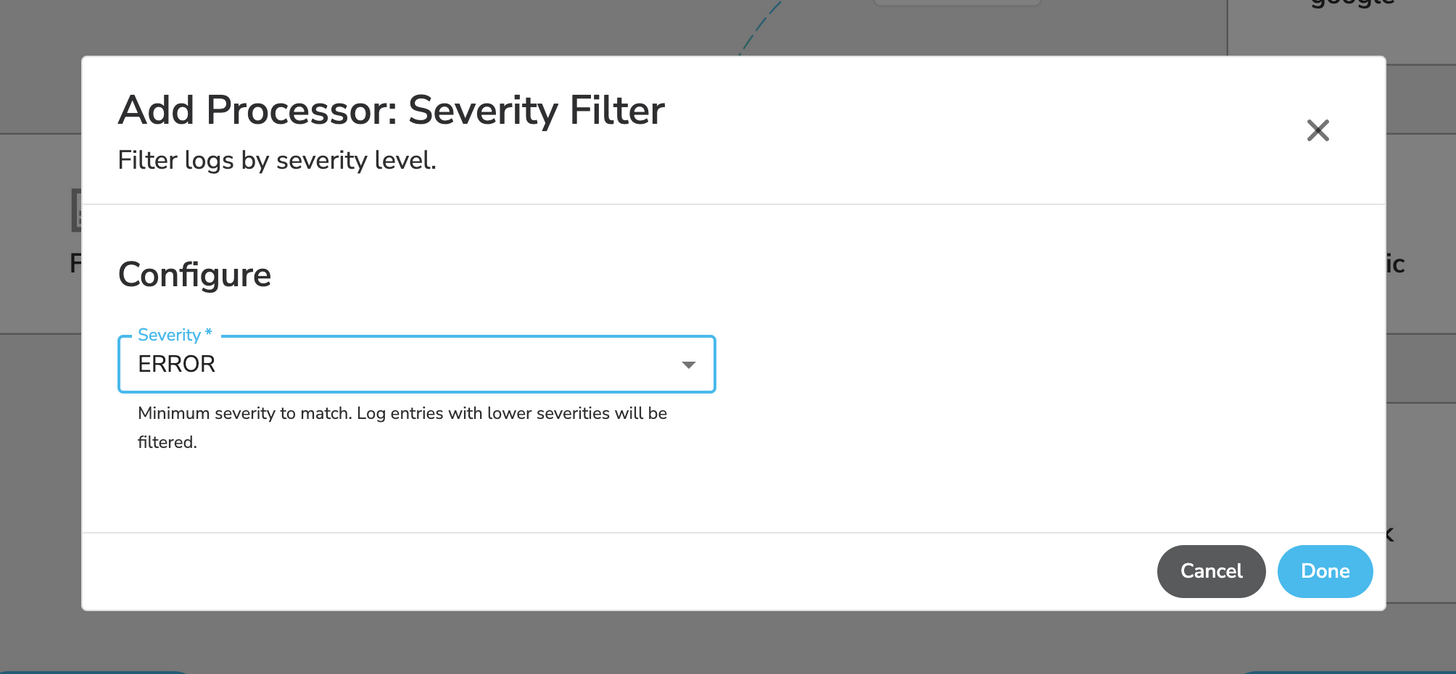
Dropping Logs
Using the “Log Record Attribute Filter” processor, you can reduce noise by excluding any logs that match a certain key-value pair. You can use either a strict [exact] match or regular expressions.
For example, let’s say that you are currently ingesting a syslog stream from an on-premise firewall, but you don’t care about entries containing a specific IP address. If you know the key=value pair that exists in the log stream, you can filter it out easily, saving on ingest costs.
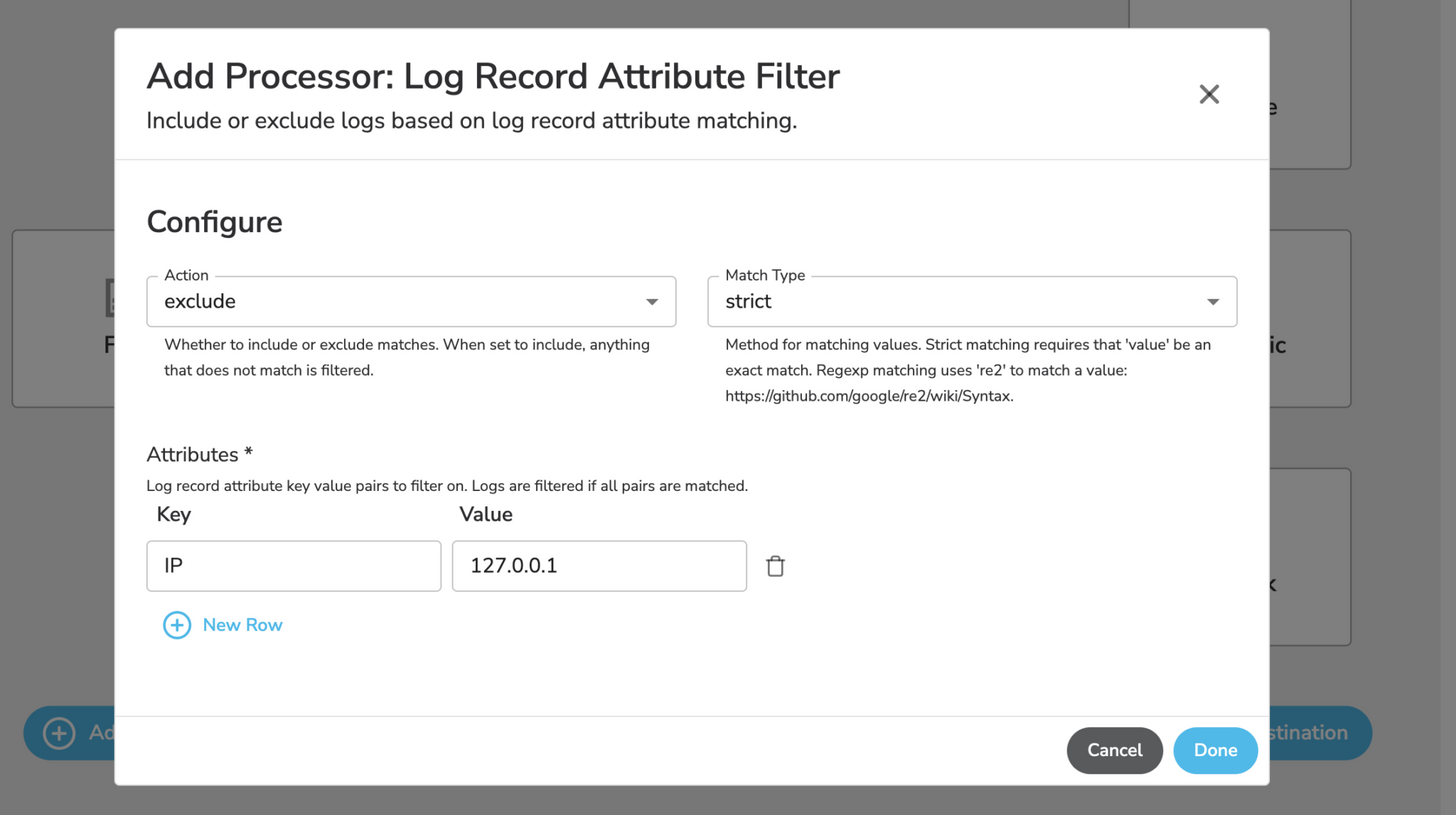
Routing
Let’s say you are currently ingesting raw log data, but you want the ability to take those logs and instead send them to a cheaper option like Google Cloud Storage. It’s also common for different teams to have different operational tools. From a single agent, we can consolidate your collection footprint. Where the observIQ BindPlane agent can send to New Relic for APM Traces, Google Cloud Operations for SRE Metrics, and Splunk for SIEM use cases.
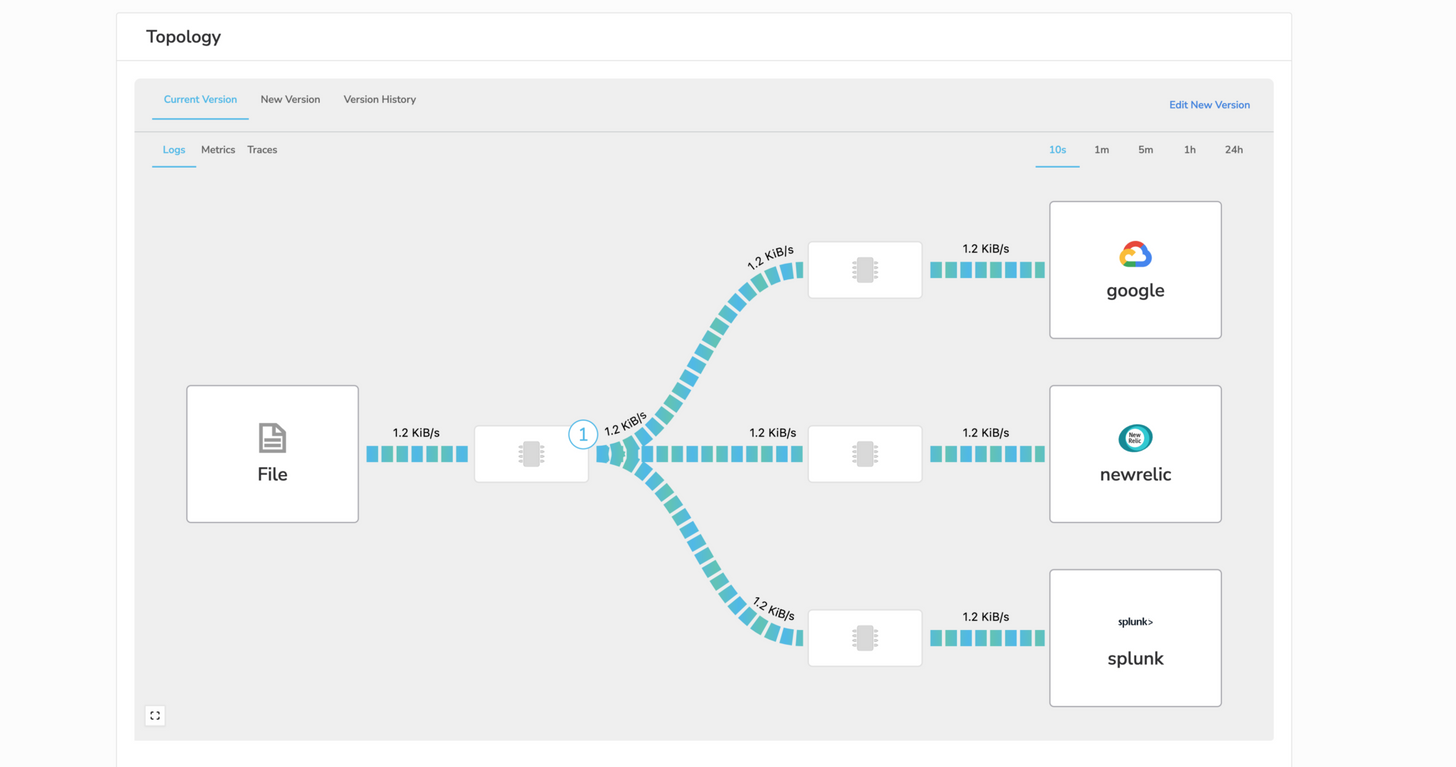
Logs to Metrics Conversion
Converting a series of raw logs to time series metrics allows you to filter out a mass amount of log data and turn them into dashboard data points you care about.
Using the Extract Metric processor, you can use Expr language to extract a certain matching field from a log entry and convert it into a metric.
Let’s say you are streaming a large set of logs from an application, with a string showing when a node is unhealthy. You can use the Extract Metric processor to match that status from the log entry, convert it into a metric, and send that metric to your observability platform for analysis. In some circumstances, this can reduce the logs ingested from that stream by 90%.
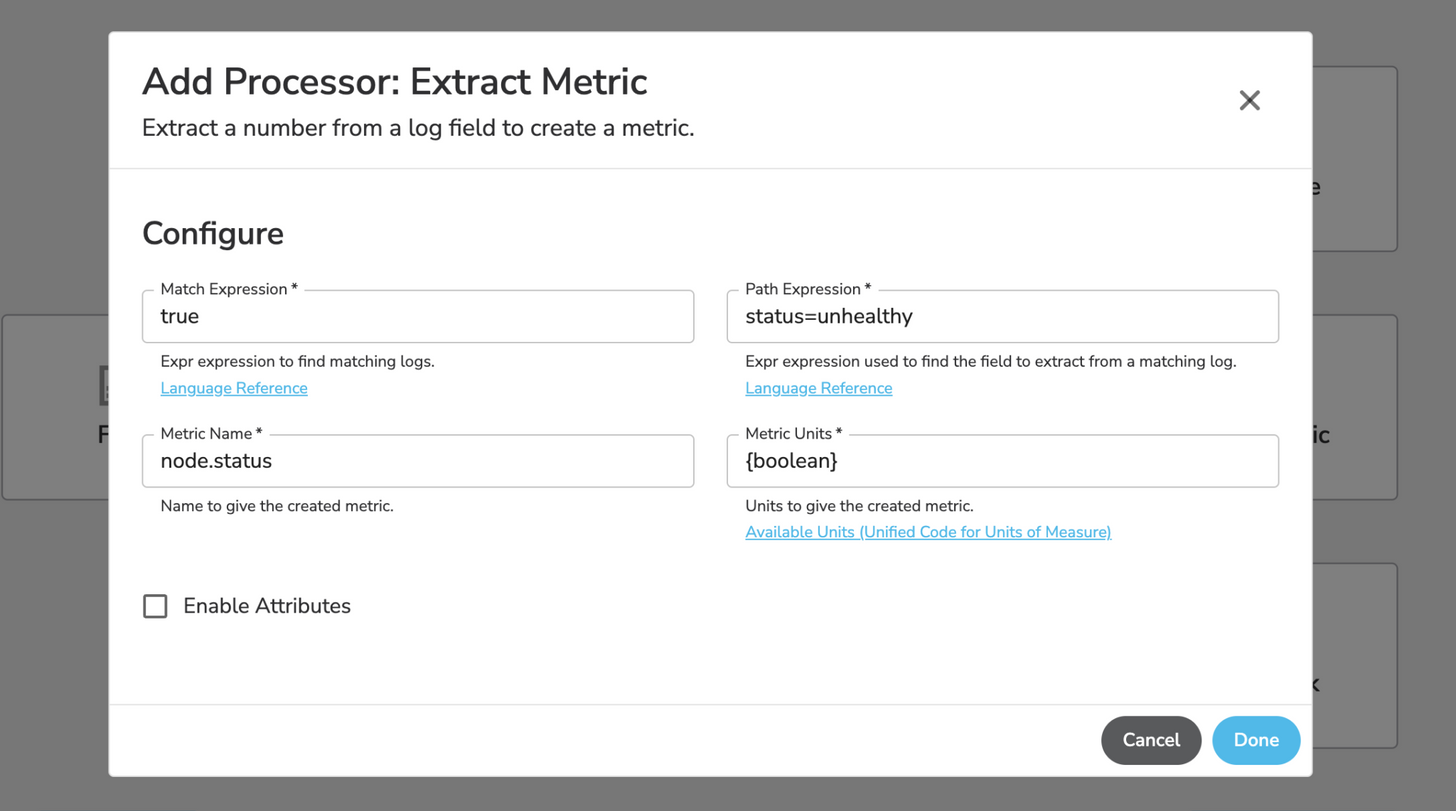
Deduplication
As stated earlier, there is often a lot of noise sent downstream that is unnecessary. Think of all those ‘200 OK’ messages in your HTTP logs. Let’s get rid of those duplicate entries and others by using the “Deduplicate Logs” processor.
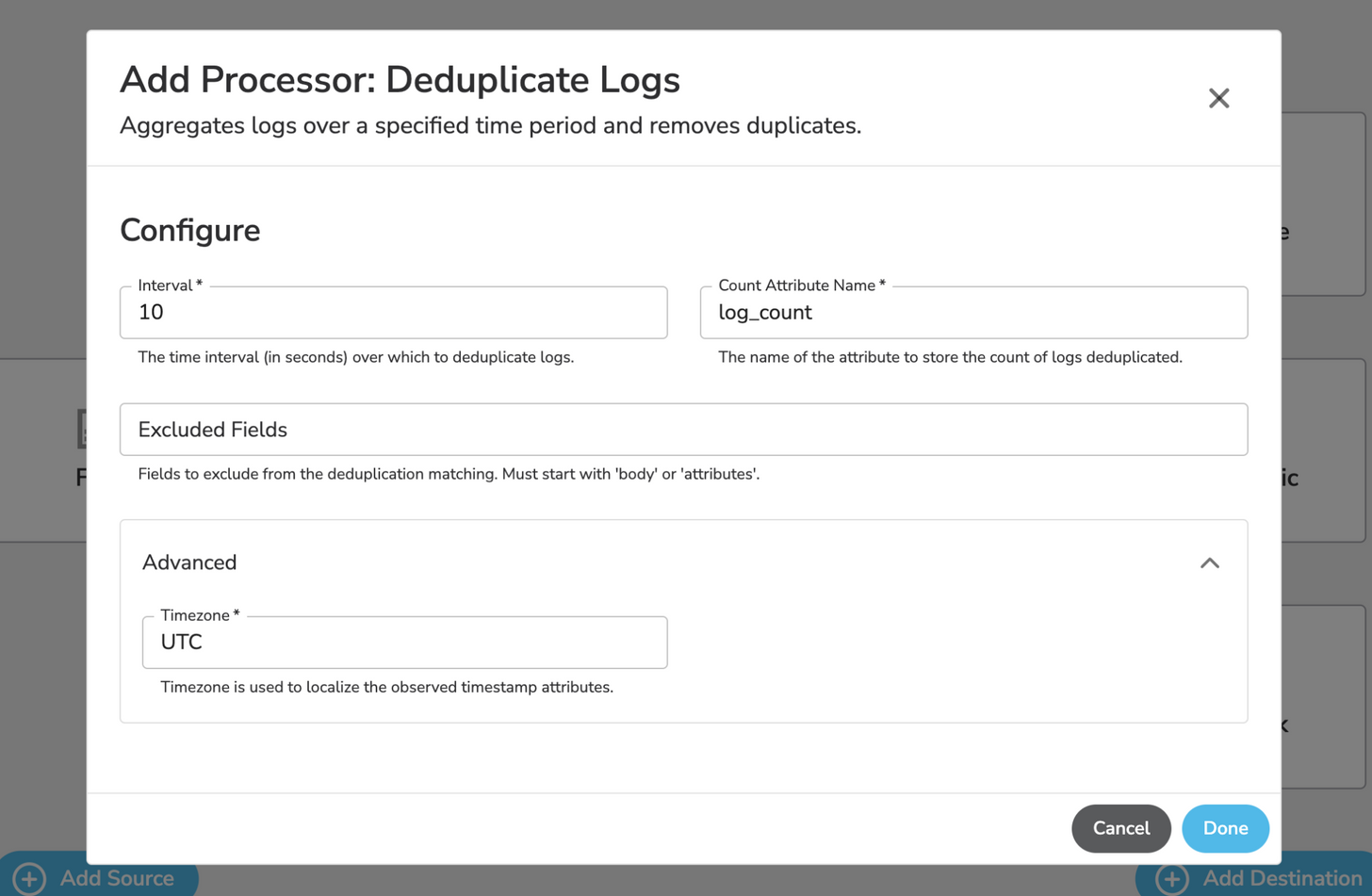
This processor will check every 10 seconds for duplicate log entries and remove them. For example, if you have 500 duplicate entries within that 10-second window, the processor will remove all of those duplicates and send only one entry to the destination. As you can imagine, the potential for cost savings here is huge.
Saving Costs with Aggregator Nodes
Replacing hundreds of vendor agents can be costly and time-consuming, and with BindPlane OP, you don’t have to. With our approach, you can leave your existing agents in place and point them to a fleet of aggregator nodes that unlock the full capabilities of BindPlane OP. In addition, these aggregators provide a secure way of passing along the data at the edge to the destination, rather than giving each agent access to the internet or API through a firewall. Save costs by reducing your overall fleet footprint, computing overhead, and consolidating virtual infrastructure.
Conclusion
BindPlane OP unleashes the power of observability by reducing costs and maximizing ROI. From filtering out trivial logs to converting raw data into meaningful metrics, BindPlane OP empowers users to make every dollar count. By embracing our innovative observability pipeline, organizations can drive efficiency, enhance data quality, and unlock the true potential of their observability investments. If you could save on your observability platform costs by ingesting only the data you truly care about, would you do it? For our customers, it was a no-brainer.
Find out what you could save by starting a conversation in our Slack community or by emailing sales@observiq.com.
Learn more about BindPlane OP:
- BindPlane OP Overview: https://www.youtube.com/watch?v=Hrqvyz_CfuU
- BindPlane OP Enterprise Features: https://docs.bindplane.observiq.com/docs/bindplane-enterprise-edition-features
- Documentation Portal: https://docs.bindplane.observiq.com/docs
- GitHub Repo: https://github.com/observIQ/bindplane-op



