Our Take On New Relic’s Observability Projections

Our take on New Relic’s observability projections for 2021
New Relic recently published a survey on the observability projections and trends for 2021. At observIQ, an emerging platform of choice in the observability space, we decided to give our users a rundown on what we agreed and disagreed with in their survey results.
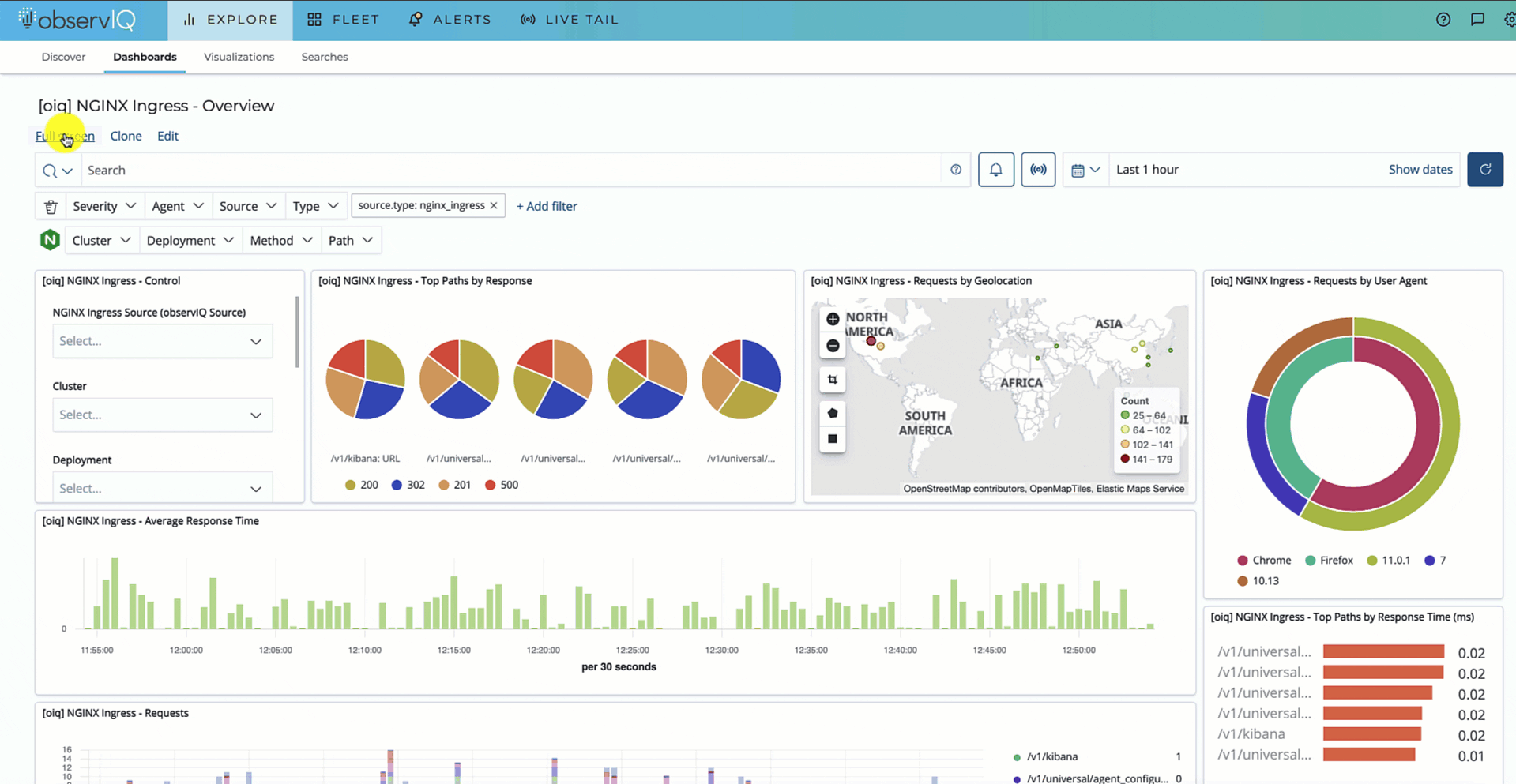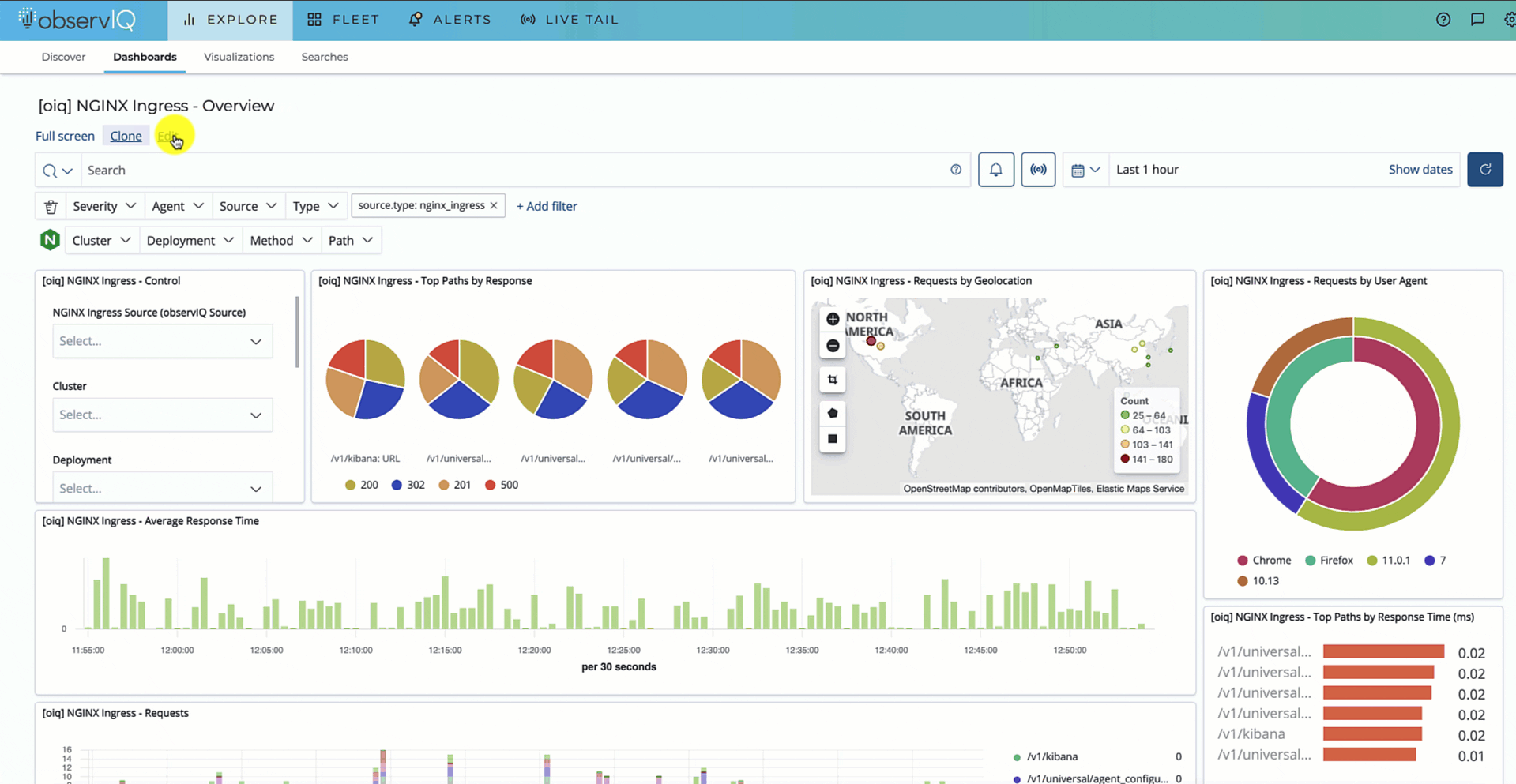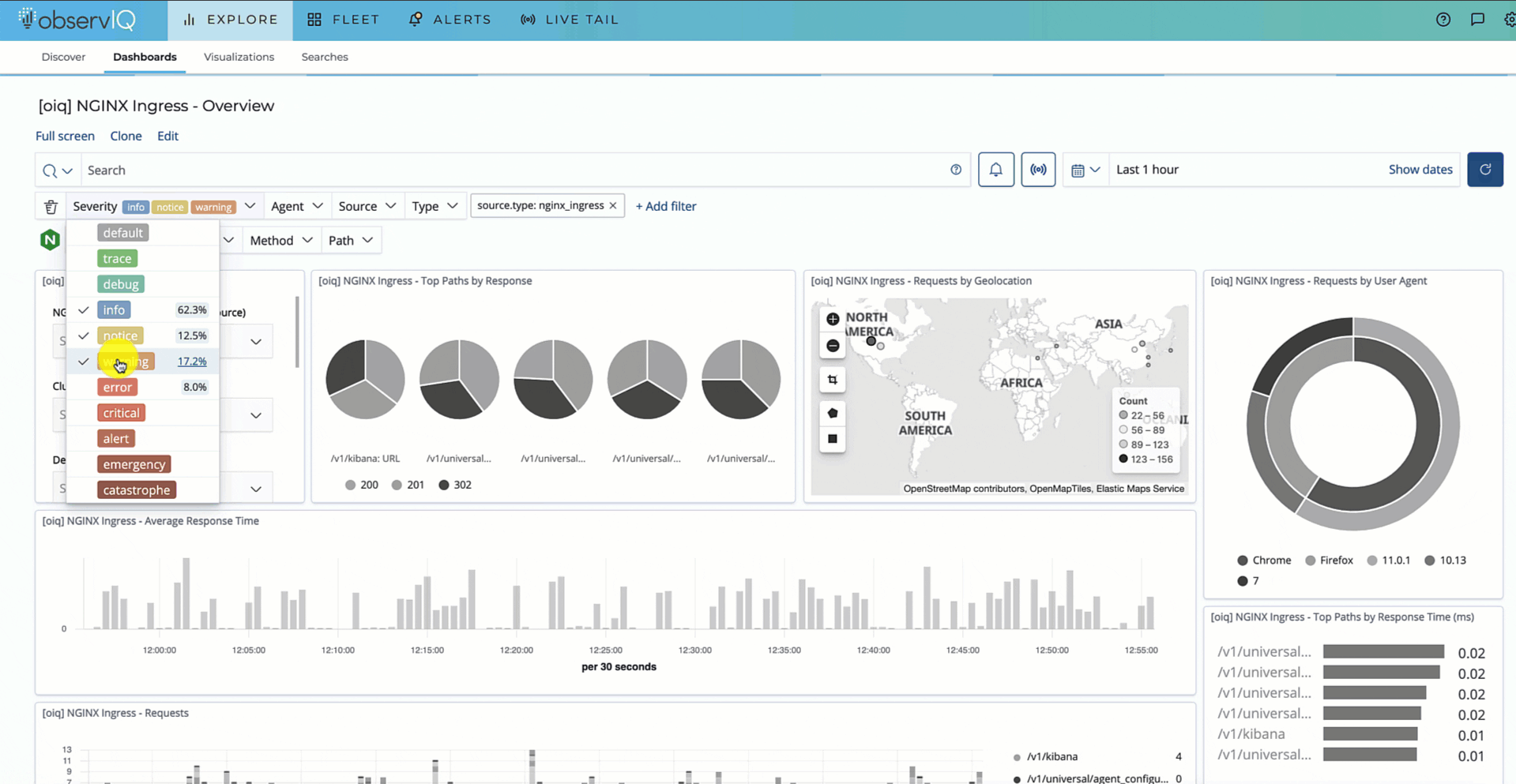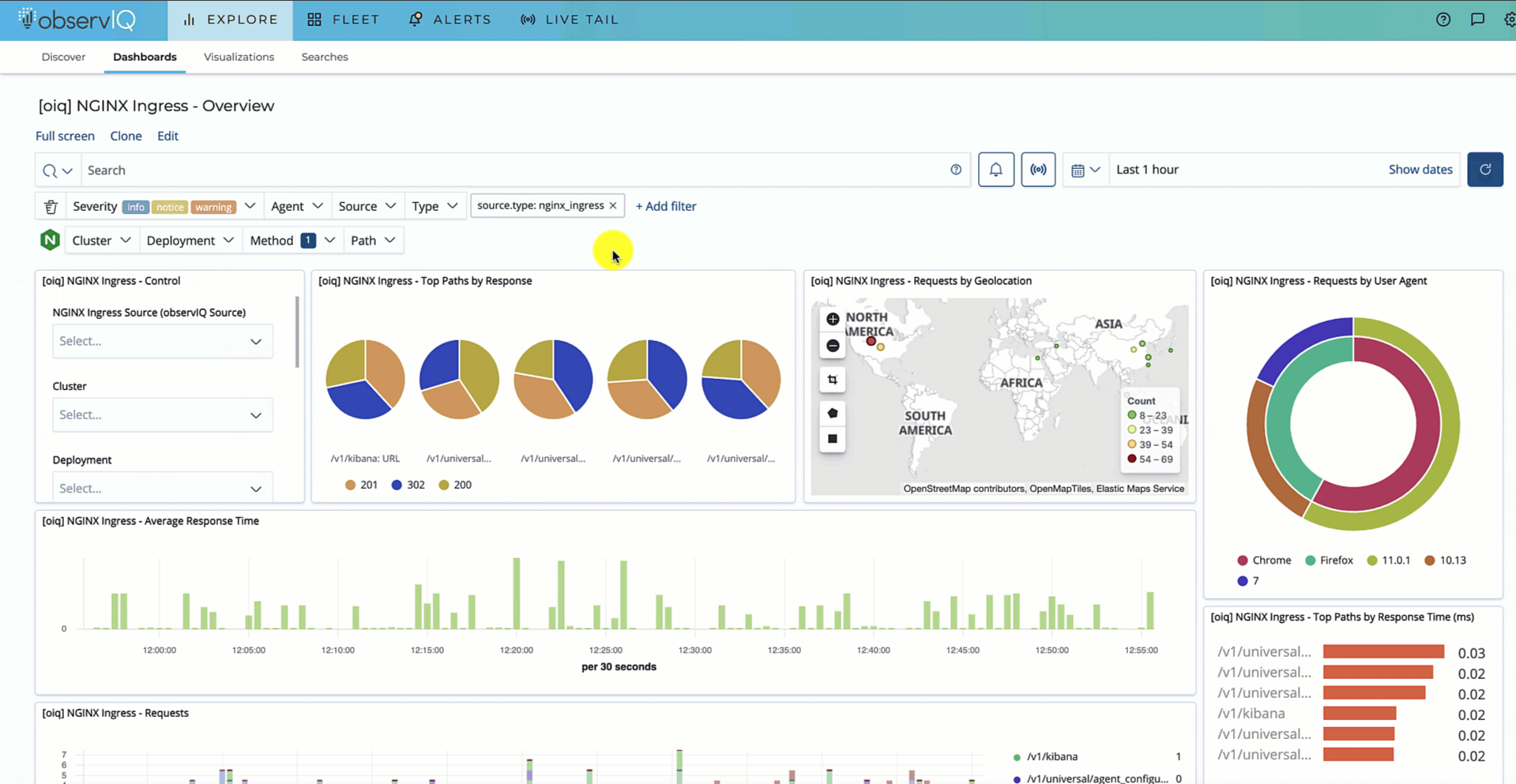
Push to Implement Observability
The survey presents a convincing argument that organizations must implement observability solutions earlier than they currently tend to. Logs help DevOps teams understand the system’s behavior through the system’s outputs, and log management has been common practice since the outset of terminals and highly hierarchical computing language. In the early 2010s, companies released application libraries installed within the application to track the application’s performance and events. This led to observability as we know it now. The difference between application monitoring and observability is cardinality. Cardinality refers to the ability to establish unique identifiers for a data set. For instance, in a database of travelers on a flight, the highest cardinality would be their passport number followed by the first name and last name combination. With high cardinality, modern observability facilitators make debugging and system performance analysis exponentially easier. This could be why more and more organizations and individuals are seeing the actual value in implementing log management for their businesses.
Effective Monitoring of Containerized Applications is the Need of the Hour
The survey reiterated that observability for Kubernetes and containerized applications is trending towards becoming a necessity. This is a no-brainer. At observIQ, we predicted this and built one of the simplest ways to plugin our agent into Kubernetes to gain visibility of all events. It is good that New Relic factored this because companies like Splunk and honeycomb.io did not include any stats related to Kubernetes adoption among businesses and the increasing need for observability among Kubernetes applications. As more and more organizations embrace containerized and micro-services-based architecture models for their applications and infrastructure, incorporating observability into their new applications is more accessible.
Observability Awareness is on the Rise
Earlier definitions of observability referred to the three pillars of observability, metrics, traces, and logs, theoretically. However, any DevOps engineer following best practices would point out that metrics, traces, and logs are merely three sets of observability data. The true sense of a functioning observability practice is using these data sets efficiently within a tool that can parse, enrich, and visualize the data.
There is No Perfect Observability Method
With distributed, containerized, and cloud applications, everything is transitory. Platforms such as OpenTelemetry have spelled out what is always known. As software systems change, processes for managing those systems are compelled to keep up with those changes. Hence, a prebuilt model that fits all businesses for the next five years has yet to exist. Observability is a space that will evolve as it needs to. For businesses to keep up with this evolution, a common ground must be formed based on processes. As per the survey, the consensus is that there is an immense opportunity to streamline and mature the observability practice, which is an agreeable statement.
Organizations Are Ready to Invest More in Observability
This brings up a seldom-talked-about question. Is an expensive solution better? We started offering a free tier in June. We did this to provide our platform to users who don’t have an exhaustive list of items in their observability wishlist. Our free tier offers short-term log data storage while maintaining your access to all existing and new features of the system. Many tools in the market offer users observability that is often tied down by the cost. Companies are limited by the price when implementing a detailed observability practice. Instead of pushing organizations to invest more in observability, the best way to make organizations embark on their observability journey would be to offer meaningful pricing. The verbiage in the survey refers to the C-suite executives making higher budgetary allocations, and it does not factor in other user personas in the fiscal study. This is an evident gap in analysis. This disparity extends to the survey’s data breakdown of the types of subscription/licensing models. Without having an inclusive user persona, these observations speak only to one specific category of users.
The Need for Engineers with Implementation Skills is a Dealbreaker in Adaptability
We agree with this statement. Companies still in the code library-based application monitoring practice find the code-level retracing and modifying very intimidating. Although some businesses see that the pros of this transition outweigh the cons, the fear of issues that may arise during implementation in a functioning system stops businesses from pursuing modern-day observability solutions. Solutions like observIQ can help users overcome the need to fix or repatch. Instead, the agents are installed onto the application stacks via preconfigured plugins.
Dev Teams Agree that Observability Should be Implemented Across the Board
We have written about how observability is now an integral part of every phase in the SDLC. The survey confirms this, with most development teams believing they need observability across the board in every application development phase, quality assurance, implementation, and maintenance. An exciting result observed from the survey is that users in the APAC region felt more compelled to incorporate observability through the SDLC than their North American counterparts.
Simple Observability Platforms to Promote Faster Implementation
The survey results tied adaptability to the skill level of an implementer. We have a different take on this. Instead of scaling up the implementation abilities of observability users, it is more efficient to build simpler observability platforms. Platforms like observIQ have a growing list of pre-built log sources. This is conducive to making organizations with smaller teams implement observability. With large, complicated observability platforms, evaluating engineers are kept from the complexity of the application.
Wider User Personas for Observability
The sampling size, occupational diversity, and geographic spread of responders used in the survey were good. However, the sample personas used seemed ancient school. Observability is no longer a restrictive space. There is an identified observability need from businesses, public entities, professional gamers, independent contractors, homeowners using IoT for home security, and technical influencers – the list of possible user personas is endless. So, having a restrictive sample pool of individuals working in similar work streams makes this survey extremely unidirectional.
Fragmented Monitoring is Still a Common Practice
One-third of the users still work with their observability data between multiple systems. With their analysis data housed in different systems, most developers must mend together siloed data manually to debug or gauge the system’s performance.
In conclusion, this survey highlights what has been known for the past few years. Observability is vertical in the tech space that is gaining momentum. The earlier the adoption, the better for organizations of all sizes. This is also the era of cloud-native application emergence. We recommend that organizations incorporate observability as part of their cloud-native migration.



