Gateways and BindPlane

The BindPlane Agent is a flexible tool that can be run as an agent, a gateway, or both. As an agent, the collector will be running on the same host it's collecting telemetry from, while a gateway will collect telemetry from other agents and forward the data to their final destination.
Here are a few of the reasons you might want to consider inserting Gateways into your pipelines:
- Collection nodes do not have access to the final destination
- Limiting credentials for the final destination to a small subset, the gateways, of systems to reduce vulnerability of exposure
- If the gateways are on a cloud instance, ability to use instance level credentials - such as for Google Cloud destinations
- Offloading data processing (parsing) to the gateways to prevent overloading of collection nodes
- Apply universal parsing to data streams coming from disparate devices
- Provide correlation to those data streams, such as trace sampling
Today, we will examine these reasons and some possible architectures for implementing gateways. We will also review how they appear in BindPlane.
Prerequisites
- BindPlane OP
- Several BindPlane agents used as edge collectors
- One or more BindPlane agents used as gateway(s)
- A final destination, such as Google Cloud Logging/Monitoring/Trace
- (Optional) Load balancer for the gateways if using more than one
Starting Point
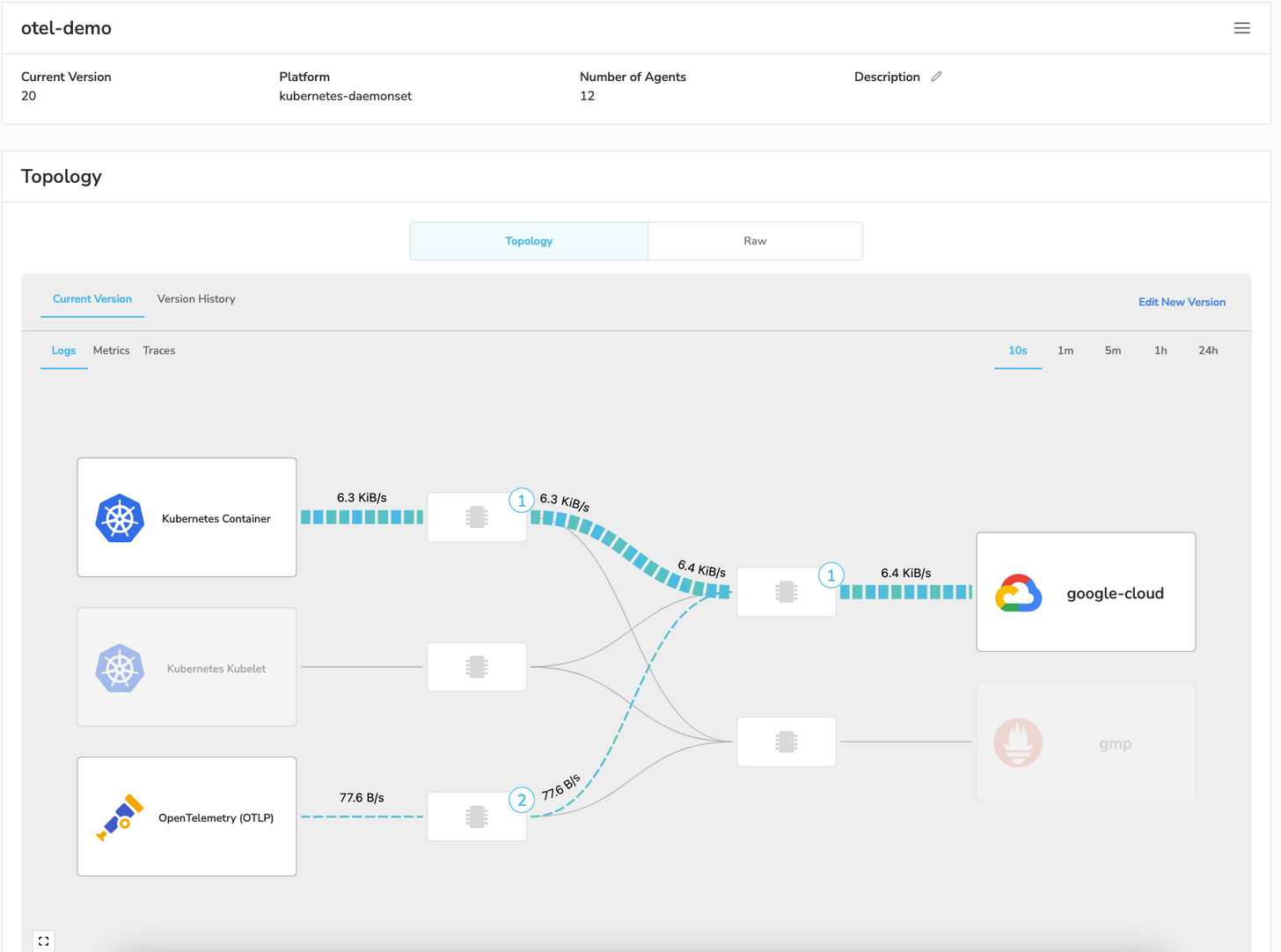
As a starting point, I am using the OpenTelemetry microservices demo running on GKE. In addition to this, I’ve created both a deployment and a daemonset of the BindPlane agent in the same cluster. For configuration, I have the generic OTel collector from the demo forwarding all data to my BindPlane daemonset. This is a sort of gateway in and of itself, but is only needed because I am not managing the embedded collector from the demo with BindPlane.
The daemonset configuration consists of a Kubernetes Container source, a Kubernetes Kubelet Source, and an OTLP source. The OTLP source is the endpoint for the data from the embedded generic collector.

And here's the configuration for BindPlane OP.
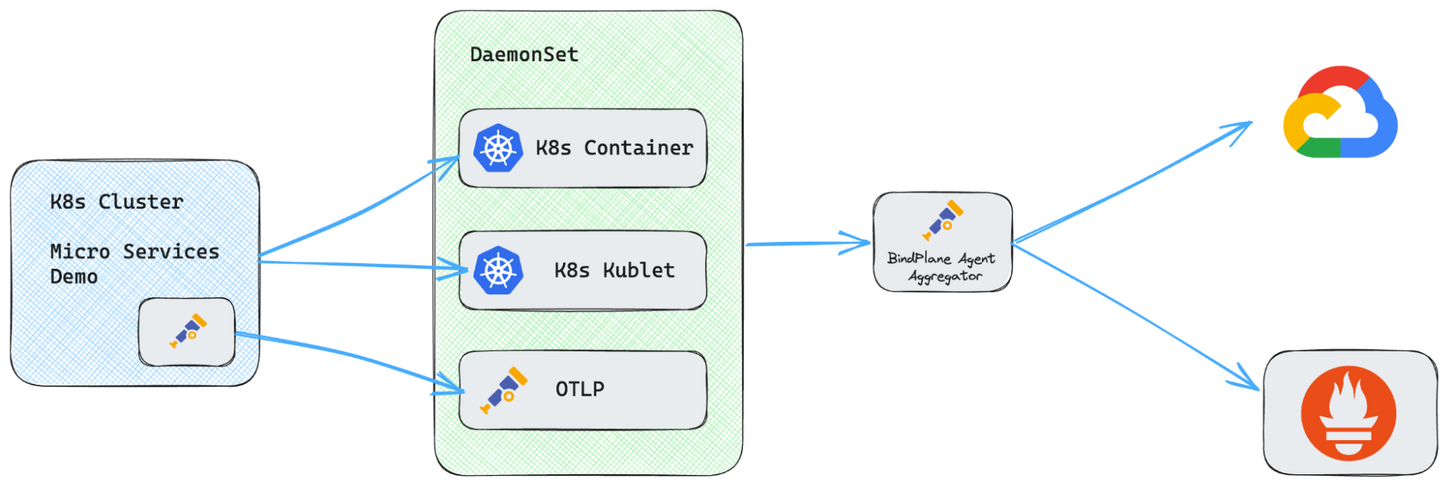
Moving To Single Node Gateway Model
We’re going to add a BindPlane agent into the pipeline as a gateway. Here is what the final architecture will look like.
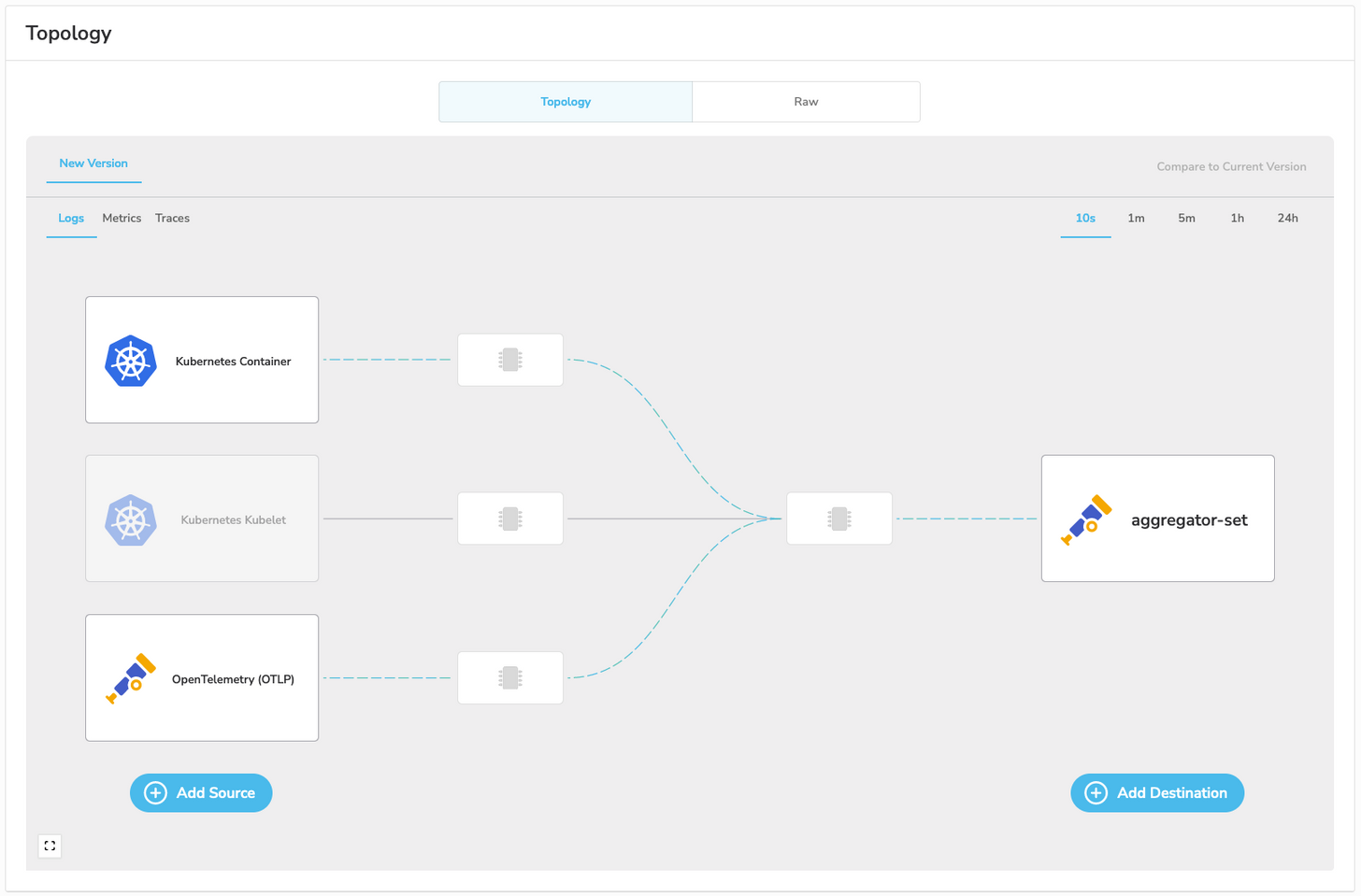
In order to convert this setup from direct to destination to an gateway model, I start by copying the configuration.

Once I’ve created the duplicate configuration, I edit it to remove all the processors and replace all the destinations with a single OTLP destination. The processor removal isn’t required. However, I am doing it to illustrate the ability to offload such processing from the edge nodes to the gateway(s). Typically, gateway nodes are dedicated systems that are well-provisioned and do nothing else. Due to those higher resources dedicated entirely to the gateway agent, performing all processing on them is often desirable. This has the added benefit of simplifying the configurations present on the edge nodes.

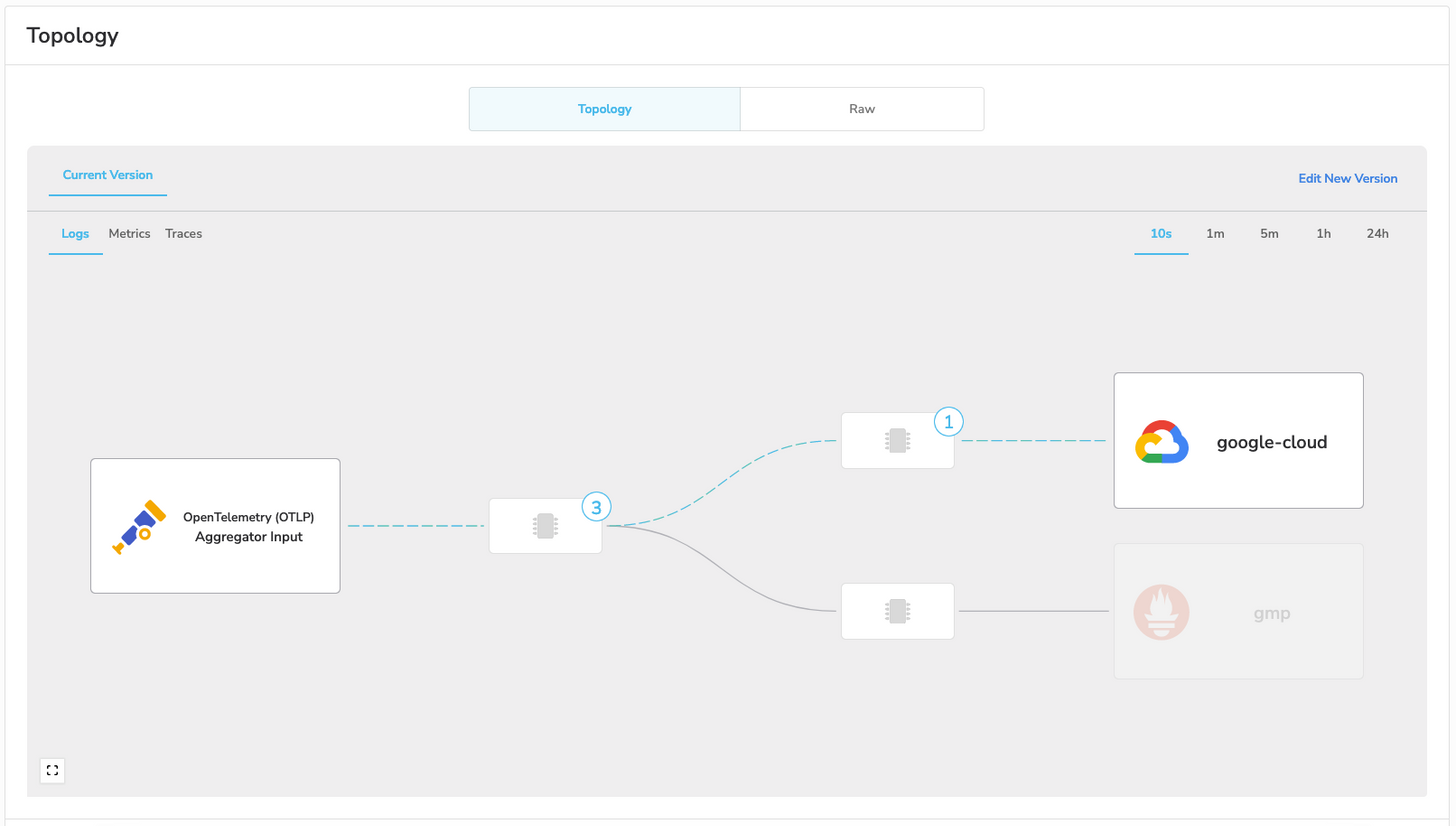
In the above screenshots, we are exporting to a single gateway on the IP 10.128.15.205. This gateway is configured with an OTLP source, the destinations previously configured on the pods, and also the processors that we removed from the pods.
Using this model, we have successfully offloaded both credentials and processors from the edge nodes. This reduces our vulnerability of credential exposure by having them present on only a single system. It also reduces the workload on the k8s pods of our edge nodes.
For simplicity and brevity, I showed the configuration of a single node gateway in this section. However, I did not apply these configurations and start the data flow. I will show the data flow at the end of the entire blog.
Related Content: Configuration Management in BindPlane OP
Moving To Multi-Node Gateway Model
The multi-node gateway model is the same as a single node, with the exception of adding a load balancer and more nodes running the gateway configuration.
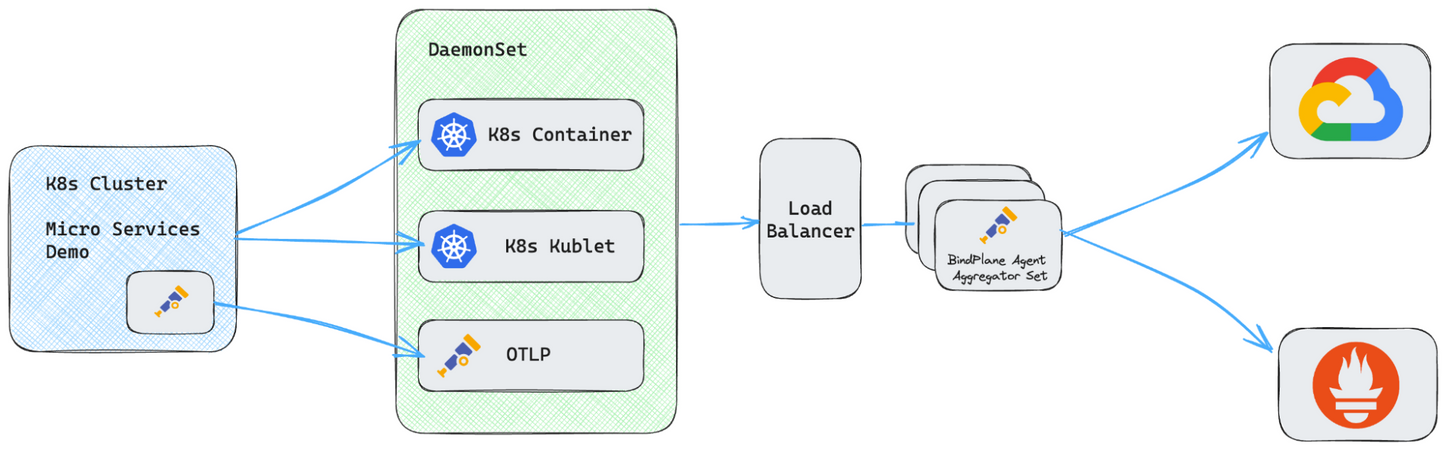
Moving to this model can be done directly from edge node or single gateway node models. Since I wanted to show both models in this blog, I am moving from the previously demonstrated gateway model.
The gateway configuration does not need any changes. It just needs to be applied to one or more additional nodes. In my case, I have a 3-node set. In front of them sits a load balancer forwarding port 4317, the GRPC OTLP port.
A single minor change does need to be made to the edge configuration. This will replace the IP of the single node, 10.128.15.205, with the ip of the load balancer, 10.128.15.208.
Related Content: A Step-by-Step Guide to Standardizing Telemetry with the BindPlane Observability Pipeline
Verifying Data Flow
Now that everything is set up and running, we can check one of our gateway nodes to validate that data is flowing.
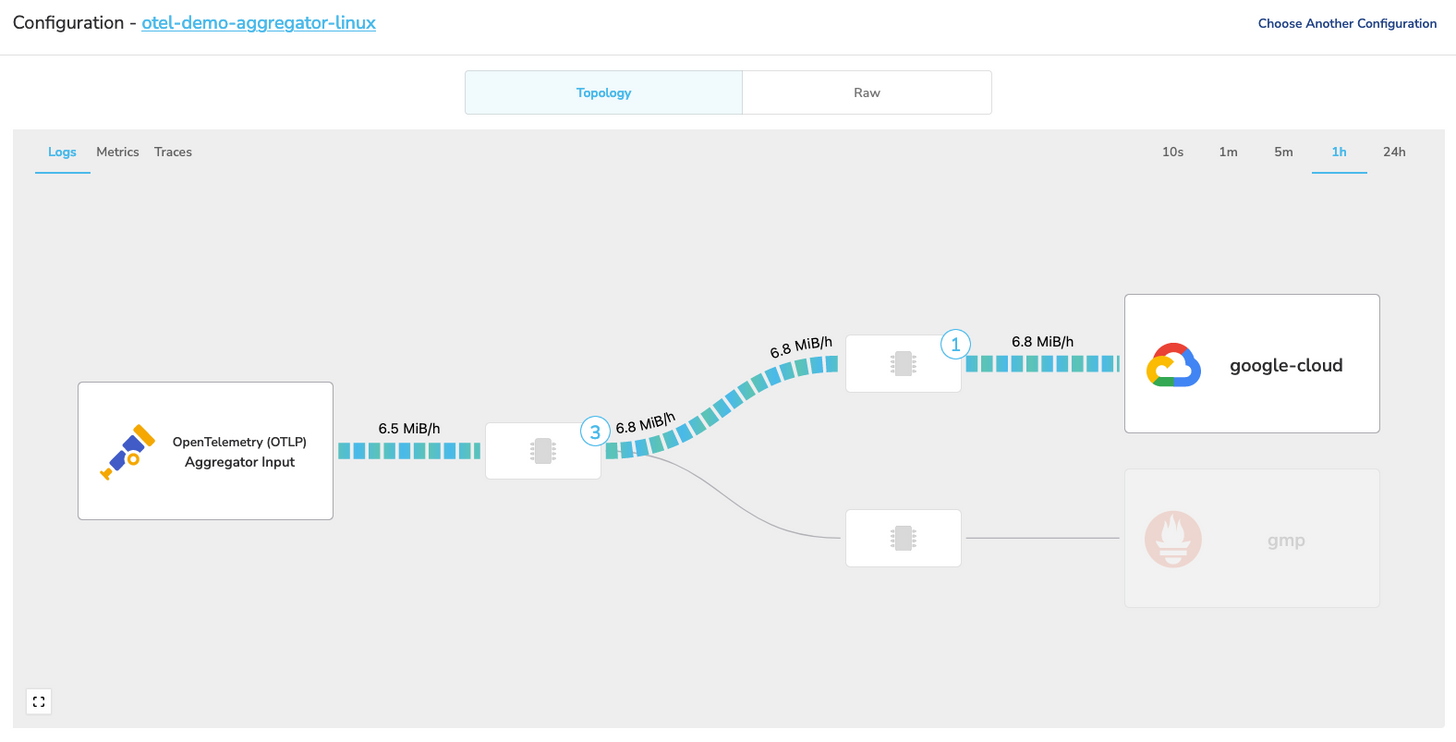
From the above screenshot, we can see that telemetry is flowing through our pipeline. We can toggle between logs, metrics, and traces to validate we’re seeing all three signals. For a final validation, we could also check our destinations. I’ll skip that today, as it has been covered in several previous posts.
Next Steps
Now that we have shifted final destinations and data processing to a gateway set, we could add additional processing to the gateway configuration.
Any time a destination change is needed, it will only affect these few nodes. The new configuration for such a change could be rolled out very fast.
Additional data inputs could be added to this configuration for direct-to-gateway sources such as syslog, raw tcp logs and metrics, and native OTLP trace instrumented applications. This sort of change would further offload work from your edge nodes.
Architectures
Today, we’ve examined two simple architectures and discussed ways to enhance them. However, other architectures for gateway exist. Touching on these briefly, with the two we examined today at the top of the list, we have:
- Single node gateway - ideal for small environments with a limited number of edge nodes
- Multi-node load balanced gateway set - scalable and ideal for most enterprise environments
- Multi-layer, multi-node gateway sets - For very large enterprise environments
- Has a gateway set per data center, region, or other division point
- These initial gateway sets will perform data processing, offloading
- The destination for these gateways will be a final load balanced gateway set that performs the transmission to the final destination(s)
- Ideally, in this large environment, the final gateway set will be distributed across multiple locations, and an intelligent load balancer will sit in front, directing traffic to the closest healthy nodes.
- Offers the most redundancy and data safety
- Traffic director gateway sets - For data segregation
- This could be a multi-layer gateway
- An initial gateway set figures out where traffic belongs and forwards that traffic
- Each directed traffic destination can go directly to the final destination or a destination gateway set in the multi-layer style above as appropriate for the volume of traffic
There are likely other setups that I have yet to consider or think of, but these are the ones we see most frequently.
Conclusion
BindPlane provides users with a robust data management environment, and gateways are one of the most important tools in the arsenal. As seen today, there are many ways in which gateways can help protect your credentials, correlate, process, and route your data. Gateways provide much-needed flexibility to your data pipeline, especially when combined with other tools, creativity, and intelligent deployment strategies.



