
ObservIQ blog








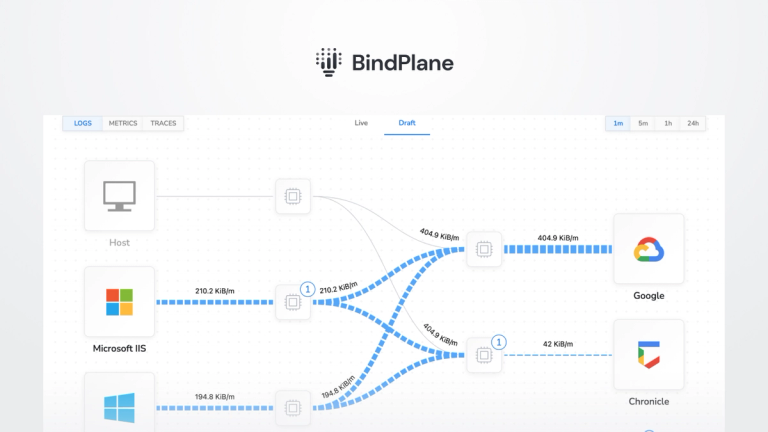







Become a part of our thriving community, where you can connect with like-minded individuals, collaborate on projects, and grow together.
Deploy in under 20 minutes with our one line installation script and start configuring your pipelines.
Try it now